Youtube Channel/Playlist to Podcast RSS Feed
2023-06-25
Preface
I listen to several Youtube channels as background noise/entertainment and many channels produce content that really don’t require a visual element. Even for channels that explicitly generate a podcast feed for their content, usually that’s gated behind some level of funding (e.g. Patreon); if I’m enjoying their content I’m perfectly fine paying for that added benefit, but there is the drawback that those feeds are often a hassle to manage. I don’t know if the state of this has changed since 2020 when I originally wrote this script, but I’ve come to use it on many channels that don’t offer this as a service anyways. On the whole, I’m still only consuming the publicly available content anyways, merely format shifting in an automated process.
General gist is going from:
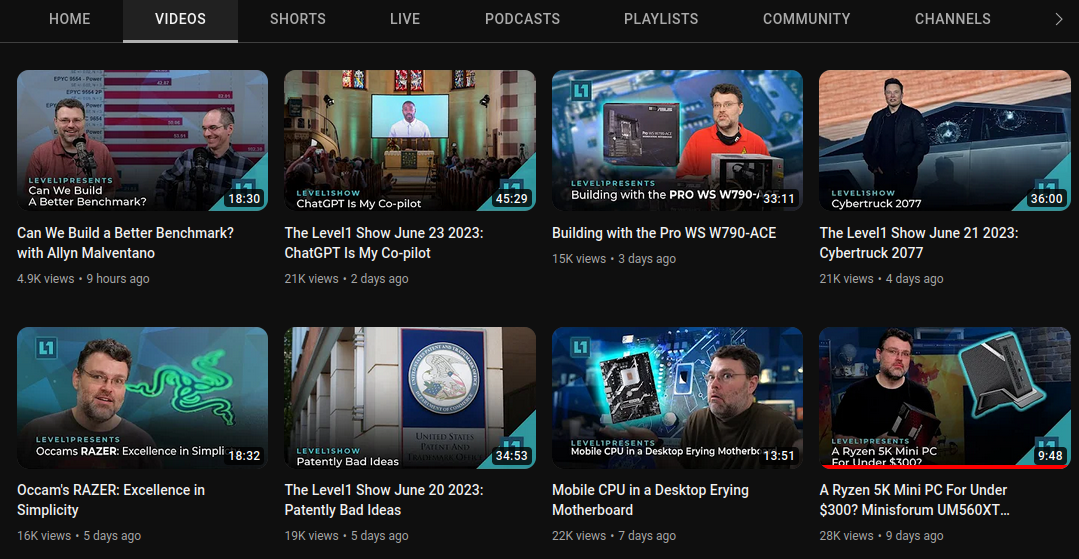
to a podcast app via a RSS feed:
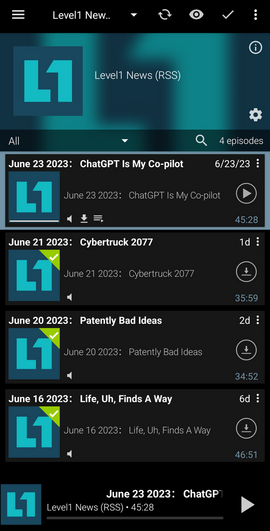
Process
Full code for the scripts located in this Github repo if that’s all you’re after - what follows is the general process the script follows, given the main dependency on yt-dlp as the standard for extracting content from Youtube at the time of writing.
- Poll the latest uploads to a channel
- Download new videos that match your given title-based criteria
- Convert to MP3, optional depending on your player of choice
- Clean up the title, optional
- Generate an RSS feed
- Notify, optional
Doing it all (mostly) in Python, given that yt-dlp is natively written in Python and has all of the features programmatically available as a module.
For the example, I’ll use a channel that consistently uploads with a fairly standardized naming scheme; otherwise, unless your target channel uploads their podcast-like content and adds it to specific playlist you can poll, I don’t really have any way of differentiating between normal videos and those which may suitable for a purely audio-based experience. For the most part, on channels that don’t have a discernible pattern, I just leave the filters off and manually ignore (i.e. just skip) anything that isn’t “podcast material.”
The first 3 steps really only require ydl.download([CHANNELID]) with a set a options, more verbosely:
1 with open("options.json") as options_file:
2 ydl_opts = load(options_file)
3
4 BASEPATH = ydl_opts["BASEPATH"]
5 PUBLICURL = ydl_opts["PUBLICURL"]
6 REMOVE_WORDS = ydl_opts["REMOVE_WORDS"]
7 CHANNELID = ydl_opts["CHANNELID"]
8
9 def download_audio(ydl_opts):
10 ydl_opts["outtmpl"] = BASEPATH + "/download/" + ydl_opts["outtmpl"]
11
12 ydl = youtube_dl.YoutubeDL(ydl_opts)
13 ydl.download([CHANNELID])options.json handles passing yt-dlp the options:
- to restrict downloads to those with titles that match a given regex,
matchtitle. In this case, they must contain “Level1 Show” or “202”. “The Level1 Show” is the name of the series (formerly “Level1 News” but they had drop “news” as it’s apparently a word that Youtube’s algorithm isn’t entirely fond of). “202” covers any video that contains the year in the title text (at least until 2030, and I find it unlikely this method or that channel will still exist, on Youtube at least, by that year); my target channel tends to put the full date in the title for each episode. - to not download anything that has already been downloaded before, using
download_archiveas a record of all successfully downloaded videos. - to download only the audio specified by
format. - to use the equivalent of the
-xargument of yt-dlp, which initiates converting the downloaded source file to an audio file of the specified format as post-processing. - to only check the last 10 downloaded episodes via
playlistend; most channels don’t upload 10 videos in a day. It’s really just an arbitrarily chosen number not expend more processing time or network calls than necessary, given the rate at which the channels are polled (multiple times a day). - to format the title to contain the upload date in a predictable manner, which we’ll use when generating the RSS feed.
1 {
2 "BASEPATH": "/var/www/html/level1",
3 "PUBLICURL": "https://web.site/level1/",
4 "REMOVE_WORDS": ["The Level1 Show", "Level1"],
5 "CHANNELID": "UU4w1YQAJMWOz4qtxinq55LQ",
6 "matchtitle": "(Level1 Show|202)",
7 "download_archive": "downloaded.txt",
8 "format": "bestaudio/best",
9 "postprocessors": [{
10 "key": "FFmpegExtractAudio",
11 "preferredcodec": "mp3",
12 "preferredquality": "256"
13 }],
14 "playlistend": 10,
15 "outtmpl": "%(upload_date>[%Y%m%d])s %(title)s.%(ext)s"
16 }A few variables needed to be passed to the script to indicate the target directory, the URL of the site that will be hosting the RSS feed, optional words to remove from the titles, and the channel/playlist ID that will be downloaded. Tacking them onto the same options file being passed to the yt-dlp constructor works as long as there is no collision of variables.
As the script isn’t always run from the target directory and I didn’t want to have to specify the same directory in the options file twice, I add to the "outtmpl" variable before passing the options to the yt-dlp construction:
1 ydl_opts["outtmpl"] = BASEPATH + "/download/" + ydl_opts["outtmpl"]There isn’t really any reason to modify the title set by the uploader, especially since 9 times out of 10 I won’t even look at the title. That being said, I did it anyways - I have the "outtmpl" option passed to yt-dlp indicate the "/download/" subdirectory for staging the files, where I then iterate over all of the files in that directory to rename and move them up to the serving directory only if they match the scheme of starting with any eight-digit representation of a date in [] as set in the "outtmpl" option.
1 def clean_files():
2 newfiles = []
3 for file in listdir(BASEPATH + "/download/"):
4 if ('.mp3' in file):
5 try:
6 filename = file.strip()
7 for word in REMOVE_WORDS:
8 filename = filename.replace(word, "").strip()
9 filename = filename.replace(" ", " ")
10
11 match = re.match(r"^\[\d{8}\]", filename)
12
13 if match:
14 newfiles.append(f'{filename}')
15 p = Path(BASEPATH + "/download/" + file).absolute()
16 parent_dir = p.parents[1]
17 p.rename(parent_dir / filename)
18 except Exception as e:
19 print("An exception occurred: ")
20 print_exc()
21 print_stack()
22 with open("new.txt", "w") as f:
23 f.writelines(file + "\n" for file in newfiles)I don’t like having my podcast app constantly updating files in the background, so I check manually for new tracks. I want to notify myself when new files are added without having to keep another log of which files I’ve already been notified of, as well as keep the notification system from mucking with the core functionality of just downloading videos and building a podcast feed. Easiest way I could think of is write the list of new files at runtime to a log that gets overwritten on subsequent runs, triggering the notification based on the contents of that file directly after the run.
I built a simple Discord bot to handle notifications for me, with the general usage of passing text to a client script that initiates a message from the bot to a private channel that I have notifications enabled for.
A bash script is called following the successful execution of the download script that iterates the contents of the new.txt file, passing each filename as an argument to the aforementioned Discord client notification script:
1 #!/bin/bash
2
3 while IFS= read -r line; do
4 python3 /home/user/docker/pdbs/client.py "NEW: $line"
5 sleep 2
6 done < new.txtI schedule the downloads to run via cron:
1 */15 1-5 * * * user /var/www/html/level1/run.sh && /var/www/html/level1/notify.shEnd result:
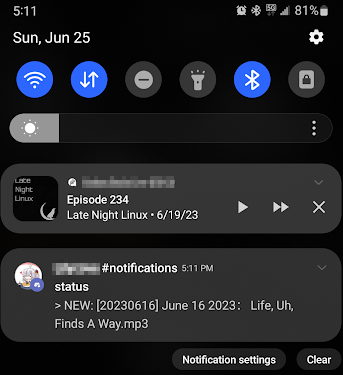
Plenty of other options regarding notifications - you could similarly use a script that instead emails yourself a notification that contains the contents of the new.txt file as the subject line for brevity since it’ll usually only be one line unless you’re targeting a very active channel:
1 cat new.txt | mail -s "$(cat new.txt)" [email protected]…assuming you’ve set up your local mail client.
RSS
With the files downloaded, titles cleaned, MP3s generated, and user (optionally) notified, last step is actually generating an RSS feed.
podcasttemplate.rss contains a basic template that the script adds newly downloaded files to as “items”:
1 <rss version="2.0">
2 <channel>
3 <title>Level1 News (RSS)</title>
4 <description>Level1 News</description>
5 <image>
6 <link>https://web.site/level1/</link>
7 <title>Level1 News (RSS)</title>
8 <url>https://web.site/level1/icon.jpg</url>
9 </image>
10 <link>https://web.site/level1/</link>
11 <item>
12 <title>June 16 2023: Life, Uh, Finds A Way</title>
13 <enclosure url="https://web.site/level1/%5B20230616%5D%20June%2016%202023%EF%BC%9A%20Life%2C%20Uh%2C%20Finds%20A%20Way.mp3" type="audio/mpeg" length="89972013" />
14 <guid>https://web.site/level1/%5B20230616%5D%20June%2016%202023%EF%BC%9A%20Life%2C%20Uh%2C%20Finds%20A%20Way.mp3</guid>
15 <pubDate>16 June 2023 08:00:00 -0000</pubDate>
16 <duration>2811</duration>
17 </item>
18 <item>
19 <title>June 20 2023: Patently Bad Ideas</title>
20 <enclosure url="https://web.site/level1/%5B20230620%5D%20June%2020%202023%EF%BC%9A%20Patently%20Bad%20Ideas.mp3" type="audio/mpeg" length="66958125" />
21 <guid>https://web.site/level1/%5B20230620%5D%20June%2020%202023%EF%BC%9A%20Patently%20Bad%20Ideas.mp3</guid>
22 <pubDate>20 June 2023 08:00:00 -0000</pubDate>
23 <duration>2092</duration>
24 </item>
25 </channel>
26 </rss>The <image> URL should point to an icon image, as that is what most podcast readers will display.
Functionally, most the code is just generating and filling in the necessary tags, but one of those tags is the duration of the audio file. For this, I had to bring in another dependency to reliably obtain that information, via the package mutagen which exposes the length via MP3(filename).info.length.
1 def generate_rss():
2 tree = xmltree.parse(BASEPATH + "/podcasttemplate.rss")
3 root = tree.getroot()[0]
4
5 files = [f for f in listdir(BASEPATH) if isfile(join("", f))]
6 files.sort()
7
8 for file in files:
9 if (".mp3" in file):
10 filename = file.split(".mp3")[0]
11 fileurl = PUBLICURL + urlparse.quote(file)
12 filelength = str(floor(MP3(file).info.length))
13 filesize = str(stat(file).st_size)
14
15 newitem = xmltree.Element('item')
16
17 eltitle = xmltree.SubElement(newitem, "title")
18 title = filename.split(filename.split("] ")[0])[1].strip()[2:]
19 eltitle.text = title
20
21 elenclosure = xmltree.SubElement(newitem, "enclosure")
22 elenclosure.set("url", fileurl)
23 elenclosure.set("type", "audio/mpeg")
24 elenclosure.set("length", filesize)
25
26 elguid = xmltree.SubElement(newitem, "guid")
27 elguid.text = fileurl
28
29 elpubDate = xmltree.SubElement(newitem, "pubDate")
30 pubDateText = filename.split("] ")[0].replace("[", "").strip()
31 pubDate = datetime.datetime.strptime(pubDateText, "%Y%m%d")
32 elpubDate.text = f'{pubDate.strftime("%d")} {pubDate.strftime("%B")} {pubDate.strftime("%Y")} 08:00:00 -0000'
33
34 elduration = xmltree.SubElement(newitem, "duration")
35 elduration.text = filelength
36
37 root.append(newitem)
38
39 tree.write(BASEPATH + "/podcast.rss")The output podcast.rss file is dumped into the directory you specified as BASEPATH - presumably, a folder being served by your chosen web hosting application.
If you don’t already have a server running a static web host, a containerized nginx or Static Web Server is a perfectly viable option that is very easy to deploy. In another application of similar design that I built with the assumption that it would run under a docker container, I included the aforementioned Static Web Server to handle serving the generated file list, as a part of the docker-compose file.